Transfer Learning in NLP
KcBERT를 활용한 Transfer Learning 학습 일지 이번 석사 졸업 논문에 댓글을 논쟁적인 측면에서 분석하는 모델을 싣고자 했는데, 태스크가 새로운 것이다 보니 충분한 양의 데이터를 확보하기도 힘들
wooodong.tistory.com
Wilson score in Python - example
How to calculate page popularity using the Wilson Score
www.mikulskibartosz.name
How Not To Sort By Average Rating
Users are rating items on your website. How do you know what the highest-rated items are?
www.evanmiller.org
from math import sqrt
def wilson(p, n, z = 1.96):
denominator = 1 + z**2/n
centre_adjusted_probability = p + z*z / (2*n)
adjusted_standard_deviation = sqrt((p*(1 - p) + z*z / (4*n)) / n)
lower_bound = (centre_adjusted_probability - z*adjusted_standard_deviation) / denominator
upper_bound = (centre_adjusted_probability + z*adjusted_standard_deviation) / denominator
return (lower_bound, upper_bound)
- 대시보드 상에서 정보량이 작은 데이터의 감성 rate 가 과대평가(?) 되는 문제 극복
- Wilson score 신뢰구간 추정 방식을 사용하여 정보량이 작은 데이터의 감성을 분석할 때 생기는 다음의 문제를 해결하고자 함.
- 감성 분석을 (긍정 - 부정) / (긍정+부정) 으로 만든 rate로 시행할 때, 다음과 같은 오류가 생김.
Case 긍정 카운트 부정 카운트 rate A 1 0 1.0 B 10 1 0.81 C 100 0 1 D 1 10 -0.81
- 감성 분석을 (긍정 - 부정) / (긍정+부정) 으로 만든 rate로 시행할 때, 다음과 같은 오류가 생김.
- A의 경우 1의 긍정 카운트를 가졌음에도 부정 카운트가 없어 rate 100%
- B의 경우 10의 긍정 카운트를 가졌음에도 1의 부정 카운트로 인해 A보다 낮은 rate를 받음. 긍정/부정 카운트가 반대인 경우에도 발생.
- C의 경우 A와 비교하여 긍정 카운트가 높음에도 A와 같은 rate 100%를 받음.
>> 극단에 단순히 긍정 또는 부정 카운트가 0에 가까운(정보량이 적은) 데이터가 몰리면서 성능이 저하(신뢰도 저하)됨.
따라서 다음과 같은 추정치를 사용하여 해당 데이터의 rate를 긍정/부정 카운트에 비례하여 감산할 필요가 있음. Wilson score 신뢰구간 추정 공식은 다음과 같음.
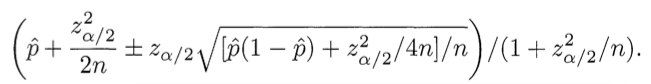
p = 이항 확률, Z alpha/2 = 유의수준 a 일 때 z score, n = 표본크기
다음의 파이썬 코드를 사용하여 a=0.05 에서 호감지수 100% 인 데이터 1건의 Wilson score 신뢰구간은 다음과 같다.
from math import sqrt
def wilson(p, n, z = 1.96):
denominator = 1 + z**2/n
centre_adjusted_probability = p + z*z / (2*n)
adjusted_standard_deviation = sqrt((p*(1 - p) + z*z / (4*n)) / n)
lower_bound = (centre_adjusted_probability - z*adjusted_standard_deviation) / denominator
upper_bound = (centre_adjusted_probability + z*adjusted_standard_deviation) / denominator
return (lower_bound, upper_bound)>>> (0.20654329147389294, 1.0)
표본크기 1에서 해당 데이터가 100%의 이항비율을 가지고 있다고 할 때, 해당 비율의 신뢰구간은 20.65% ~ 100.00% 사이. 신뢰 구간의 하한선(20.65%) 을 해당 데이터의 rate로 사용하는 것이 일반적인 방식인가보다.
'공부 > 통계' 카테고리의 다른 글
| Z-Score, Modified-Z-Score (0) | 2023.08.01 |
|---|